Frog&Duck
SEO workflow pro obří crawly Screaming Frogem
Marek Prokop, PROKOP software s.r.o.
![]()
![]()
Proč Screaming Frog
- Průmysový standard.
- Zvládá velké weby (i miliony adres).
- Exportuje použitelná data.
- Dělá chyby, ale jdou řešit.
Proč DuckDb
- Rychlá databáze speciálně na analytiku.
- Zvládne miliony řádků a desítky GB dat.
- Funguje lokálně, nepotřebuje server.
- Provoz zvládnete i bez IT podpory.
- Přístup i z Pythonu, R a dalších jazyků.
- Autoři jsou sympaťáci.
Před lety jsem na velké crawly používal BigQuery + Looker Studio, ale byl to šílený opruz.
Rozhraní k DuckDb
- CLI
- vlastní GUI
- IDE (TablePlus, Beekeeper Studio, DBeaver, VSCode + extension)
- programovací jazyky (Python, R, Node.js, PHP…)
- AI + MCP server
Kompletní workflow
Crawl
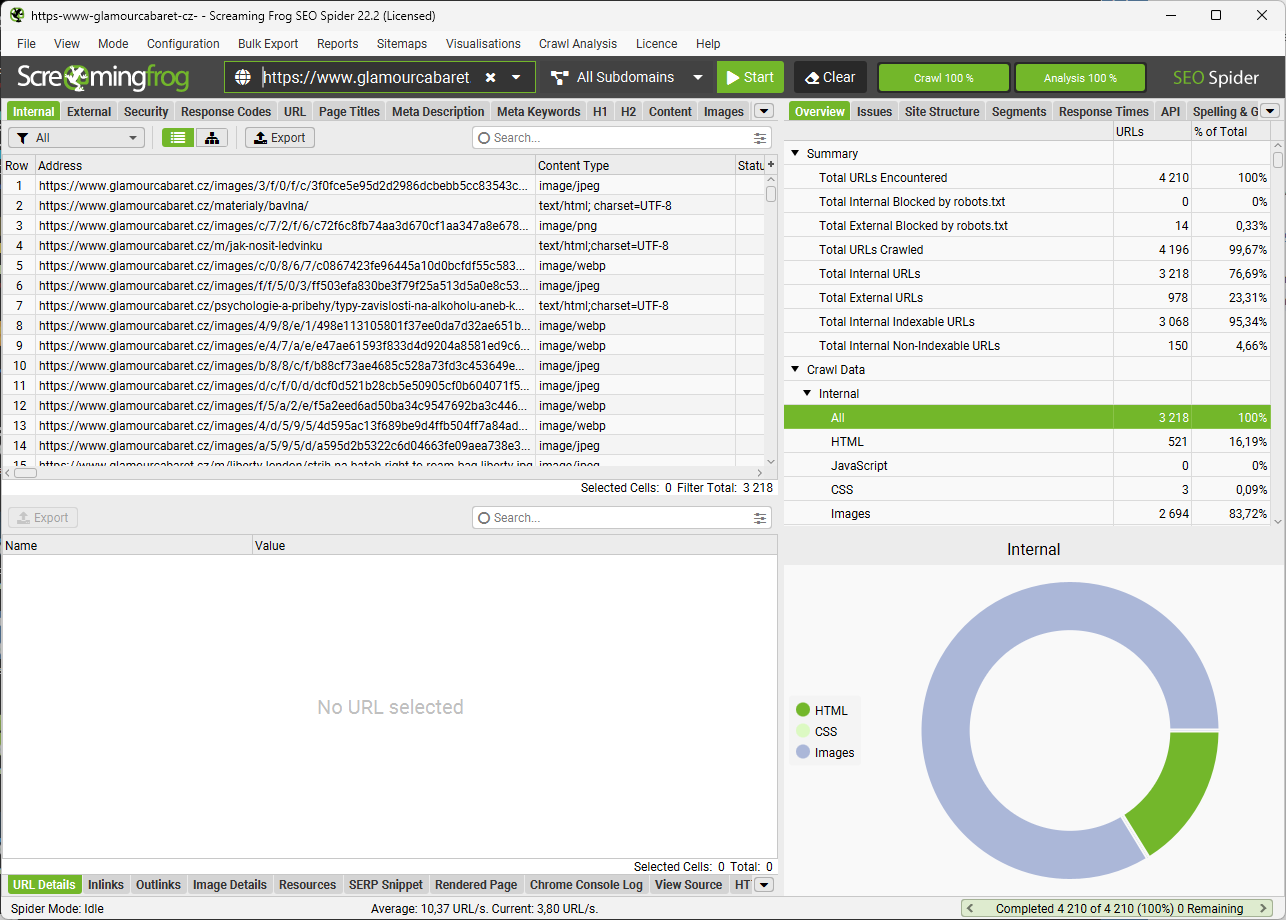
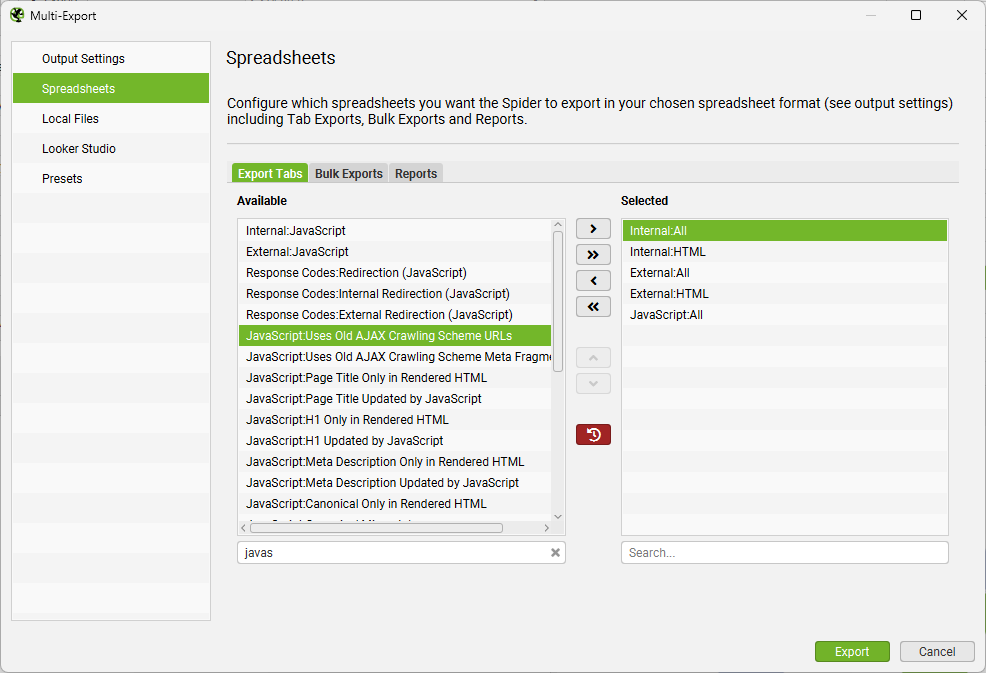
Export CSV
Otevřu terminál
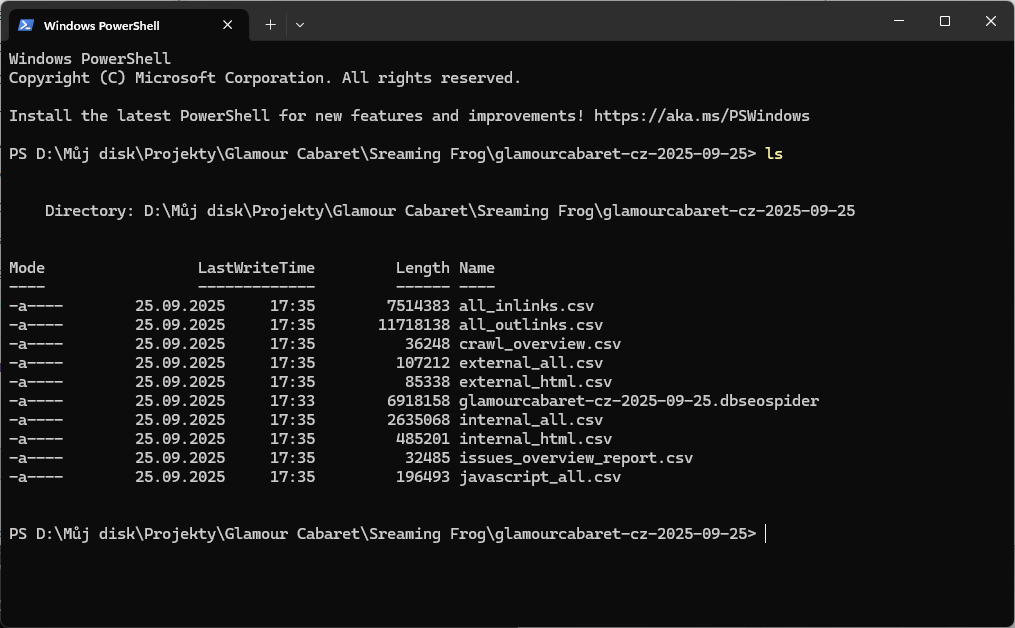
Spustím DuckDb a založím databázi
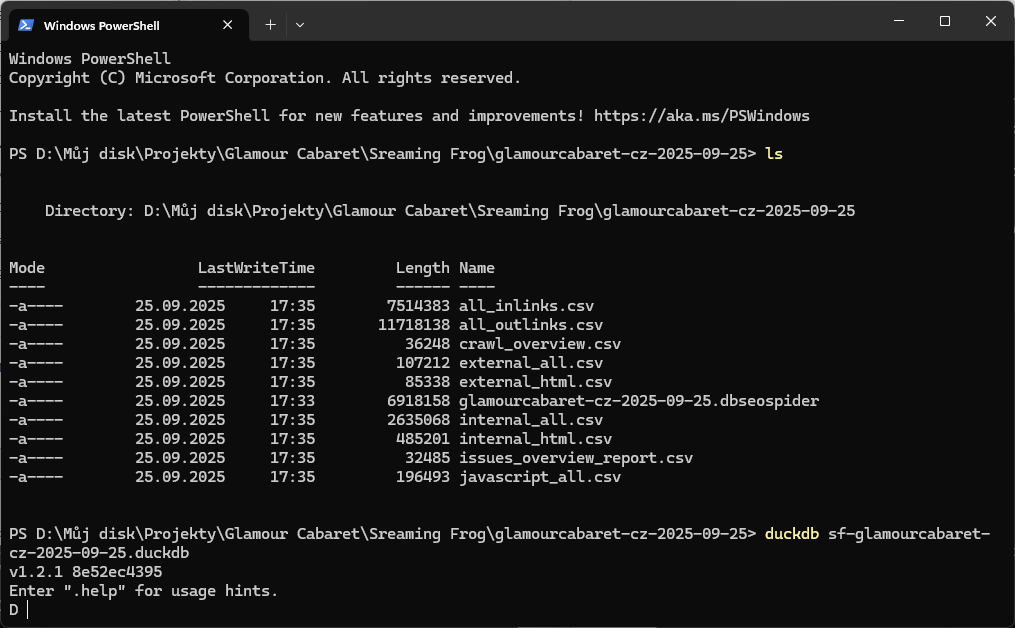
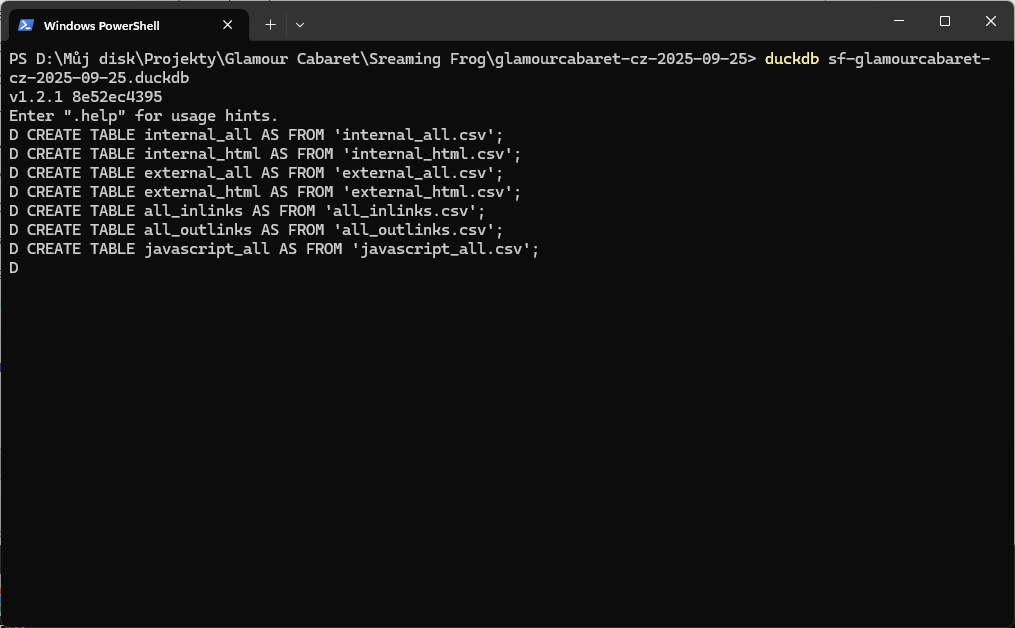
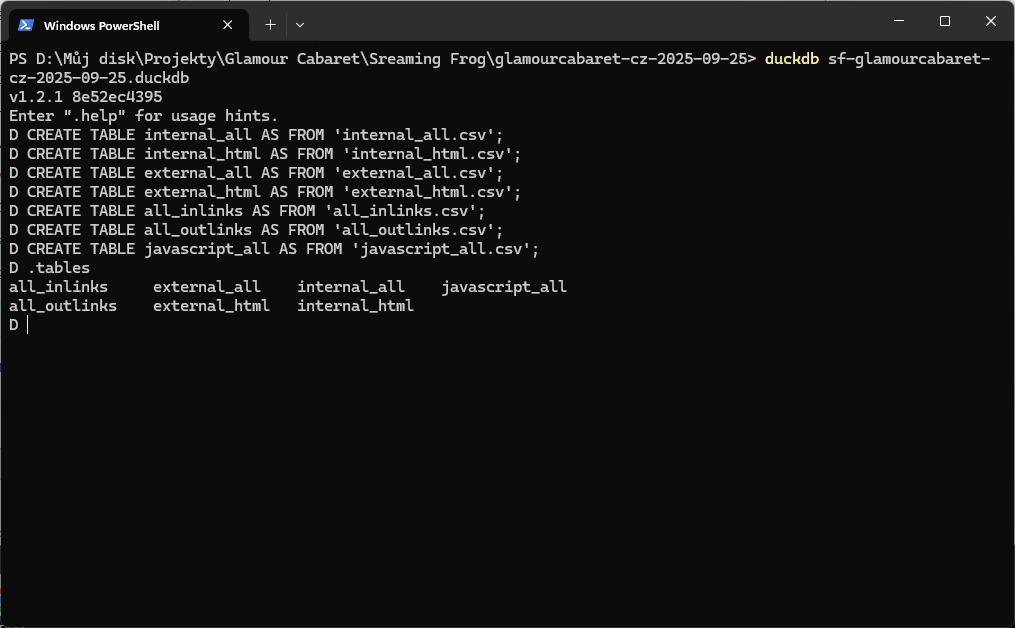
Importuju CSV soubory
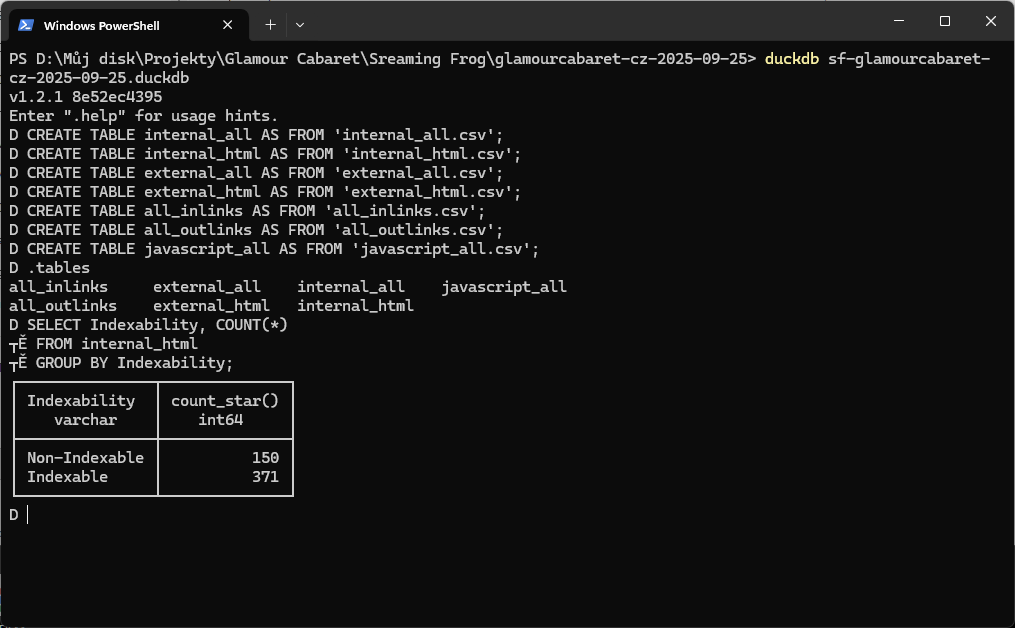
Ověříme, že jsou data OK
Zkusím jednoduchý dotaz
Ukončím příkazem .quit
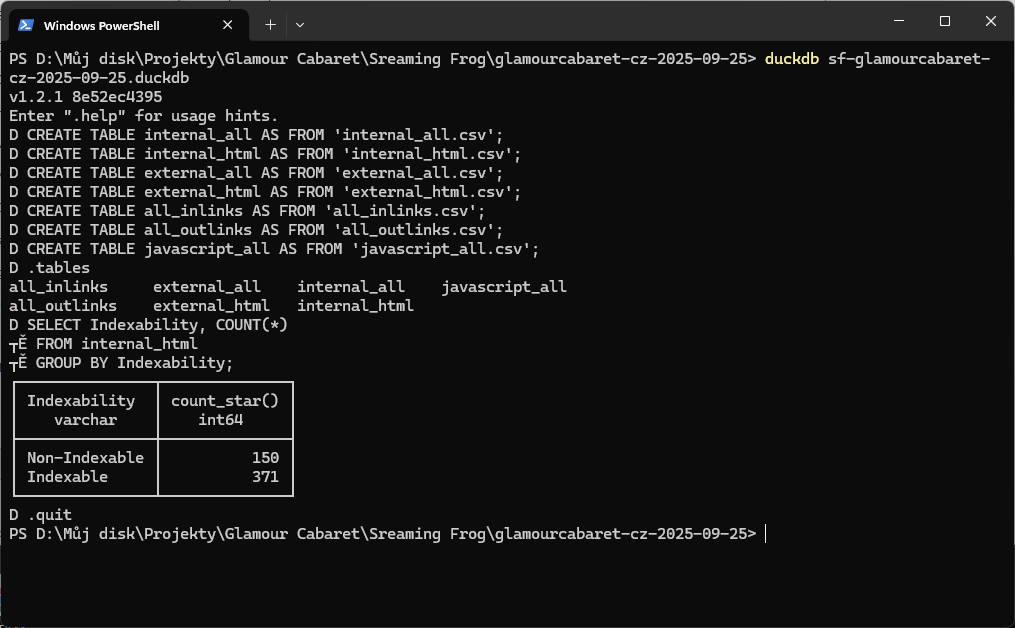
Shrnutí importu
Spuštění DuckDb
Import CSV souborů
CREATE TABLE internal_all AS FROM 'internal_all.csv';
CREATE TABLE internal_html AS FROM 'internal_html.csv';
CREATE TABLE external_all AS FROM 'external_all.csv';
CREATE TABLE external_html AS FROM 'external_html.csv';
CREATE TABLE all_inlinks AS FROM 'all_inlinks.csv';
CREATE TABLE all_outlinks AS FROM 'all_outlinks.csv';
CREATE TABLE javascript_all AS FROM 'javascript_all.csv';Ukončení
DuckDb GUI
Spustím DuckDb s databází a GUI
Tedy například:
GUI se otevře v prohlížeči
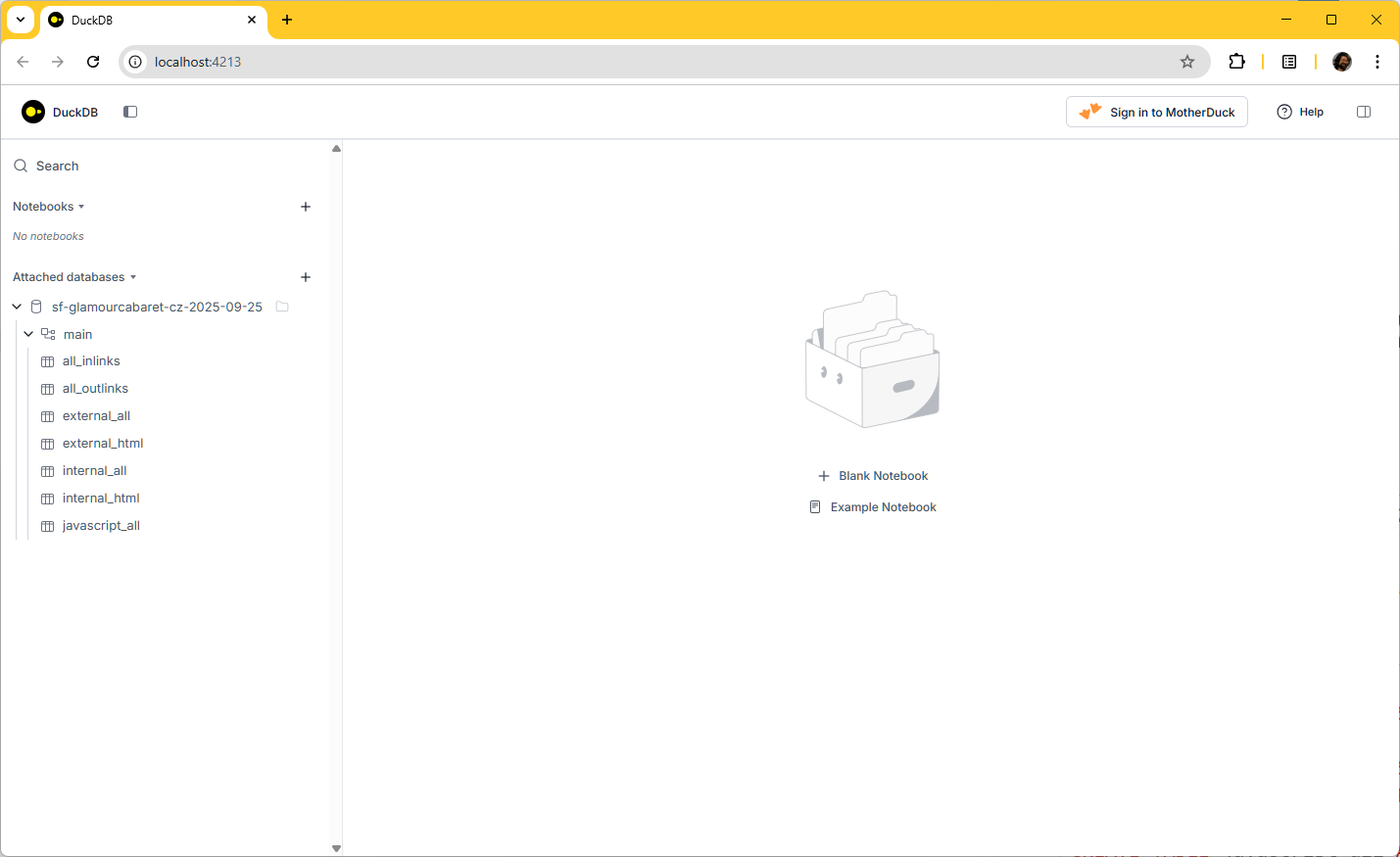
Zobrazím si strukturu tabulky
Založím notebook
Přidám buňku s SQL dotazem
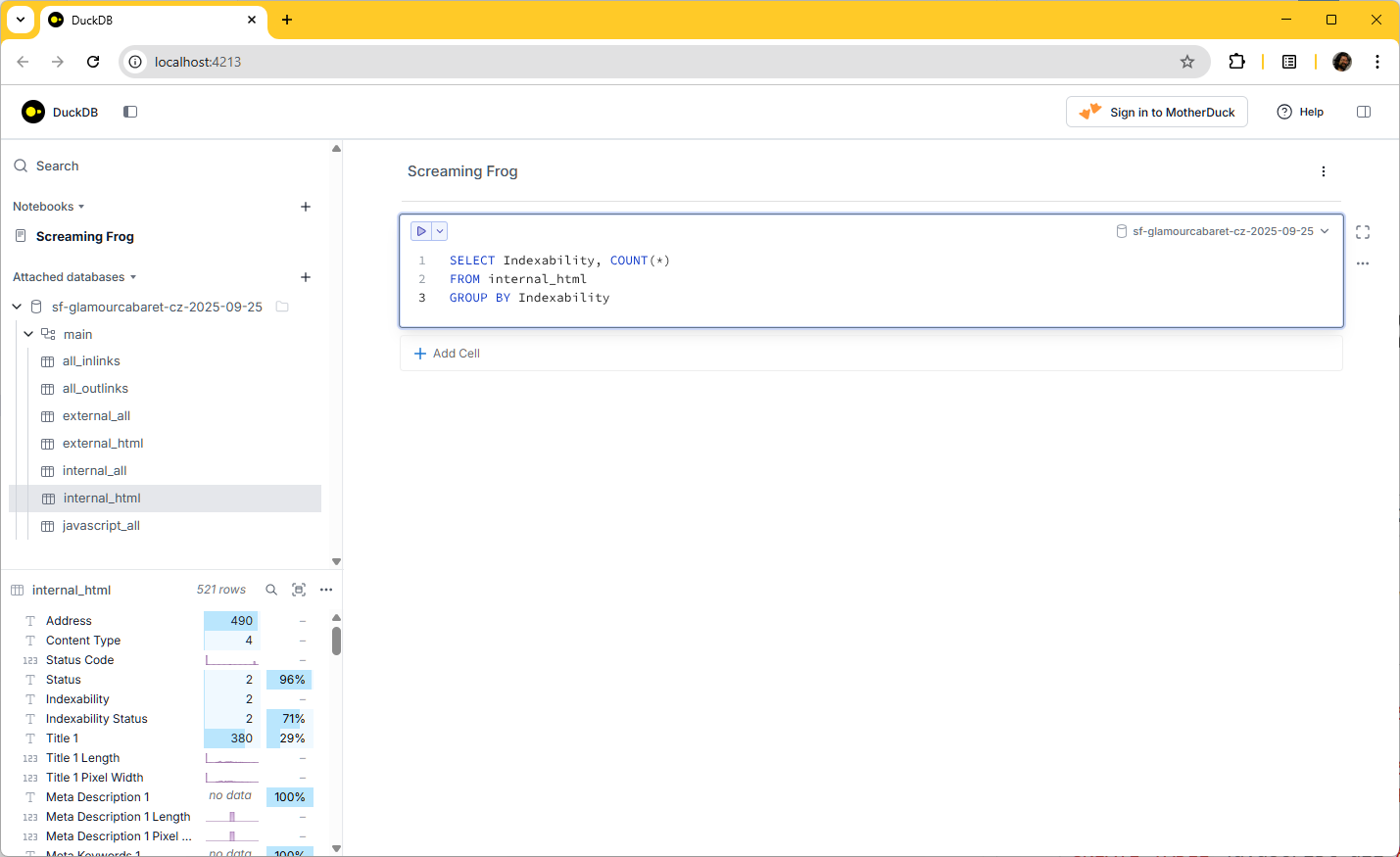
Spustím SQL dotaz
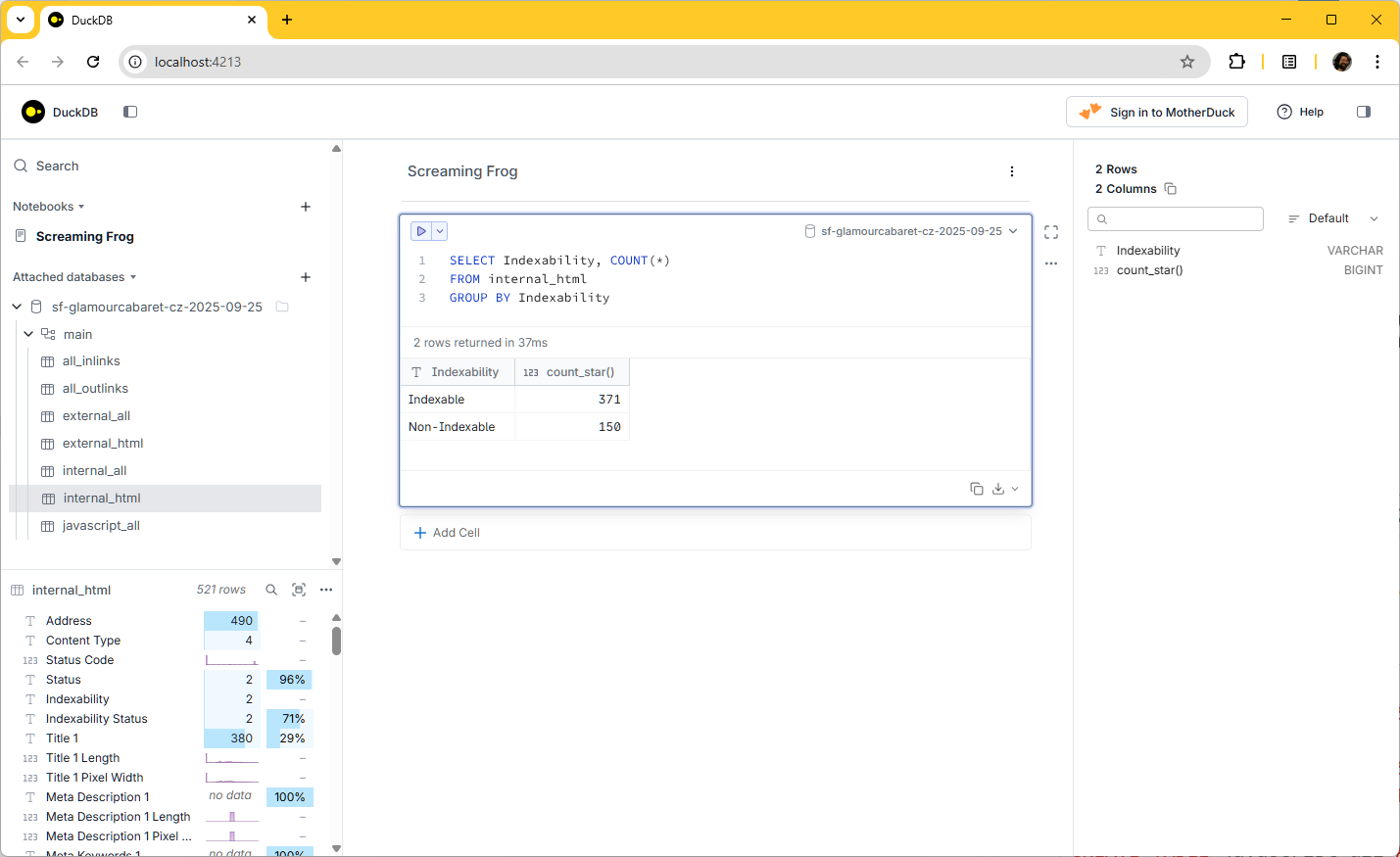
Přidám další buňku a spustím
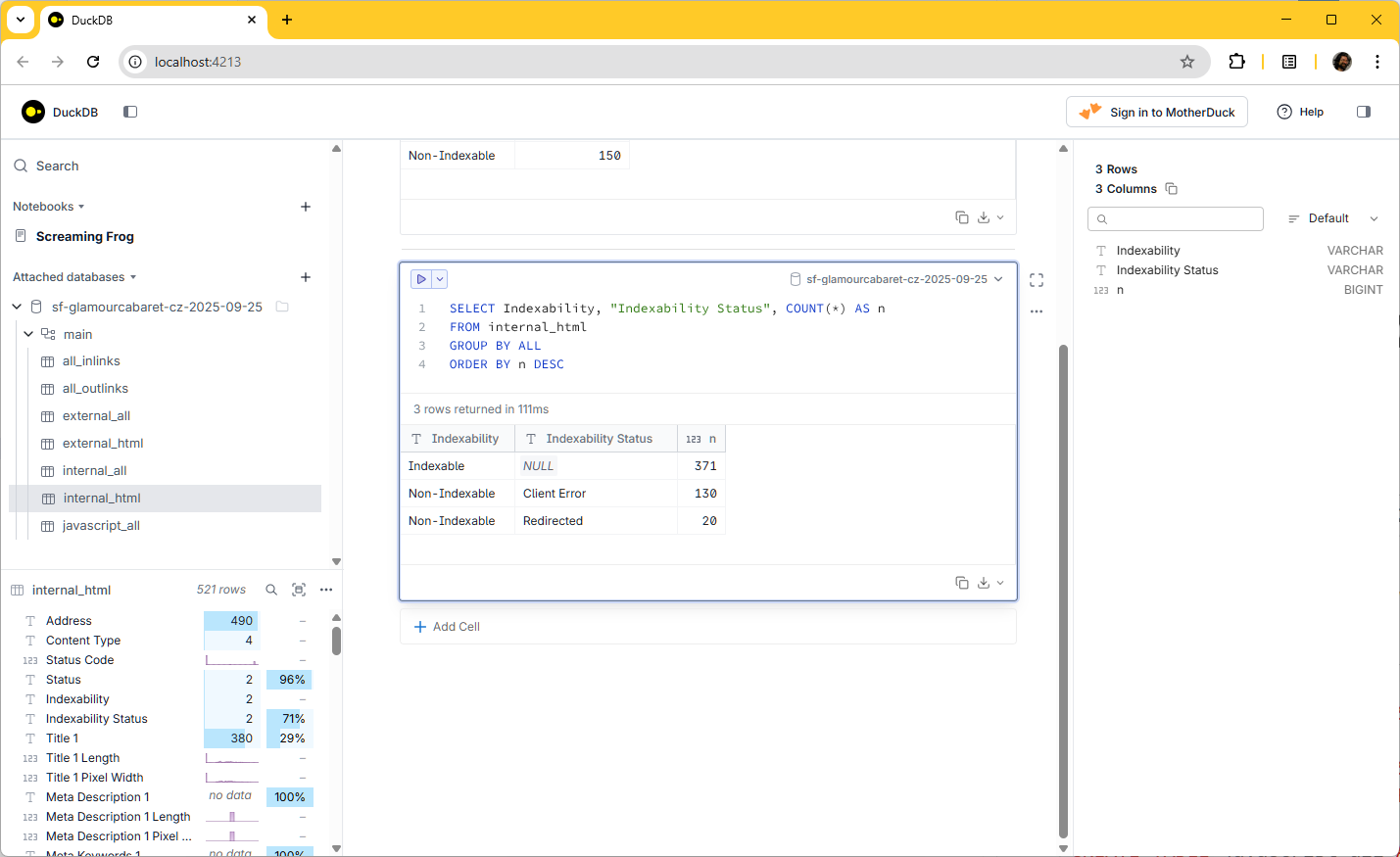
Výhody a nevýhody DuckDb GUI
Výhody
- Přehledné, hezky zobrazuje data.
- Napovídá klíčová slova SQL a sloupce tabulek.
- Výsledky dotazů jdou snadno kopírovat a exportovat.
- Můžete mít připravený notebook s SQL dotazy.
Nevýhody
- Experimentální funkce, ne zcela bez chyb.
- UX by mohlo být ještě o dost lepší.
Alternativy k DuckDb GUI
- IDE (TablePlus, Beekeeper Studio, DBeaver, VSCode + extension)
- programovací jazyky (Python, R, Node.js, PHP…)
- AI + MCP server
AI
Jak zprovoznit MCP
Poradí vám článek Close the Loop: Faster Data Pipelines with MCP, DuckDB & AI
Pokud jste líní studovat, zkuste prompt:
Na základě článku https://motherduck.com/blog/faster-data-pipelines-with-mcp-duckdb-ai/ bych si chtěl zprovoznit MCP server, přes který bych se mohl dotazovat na lokálně uložená data v DuckDb databázi. Pro dotazování použiju Claude Destop. Pomůžeš mi to zprovoznit?Claude Desktop
Připojím dabatabázi
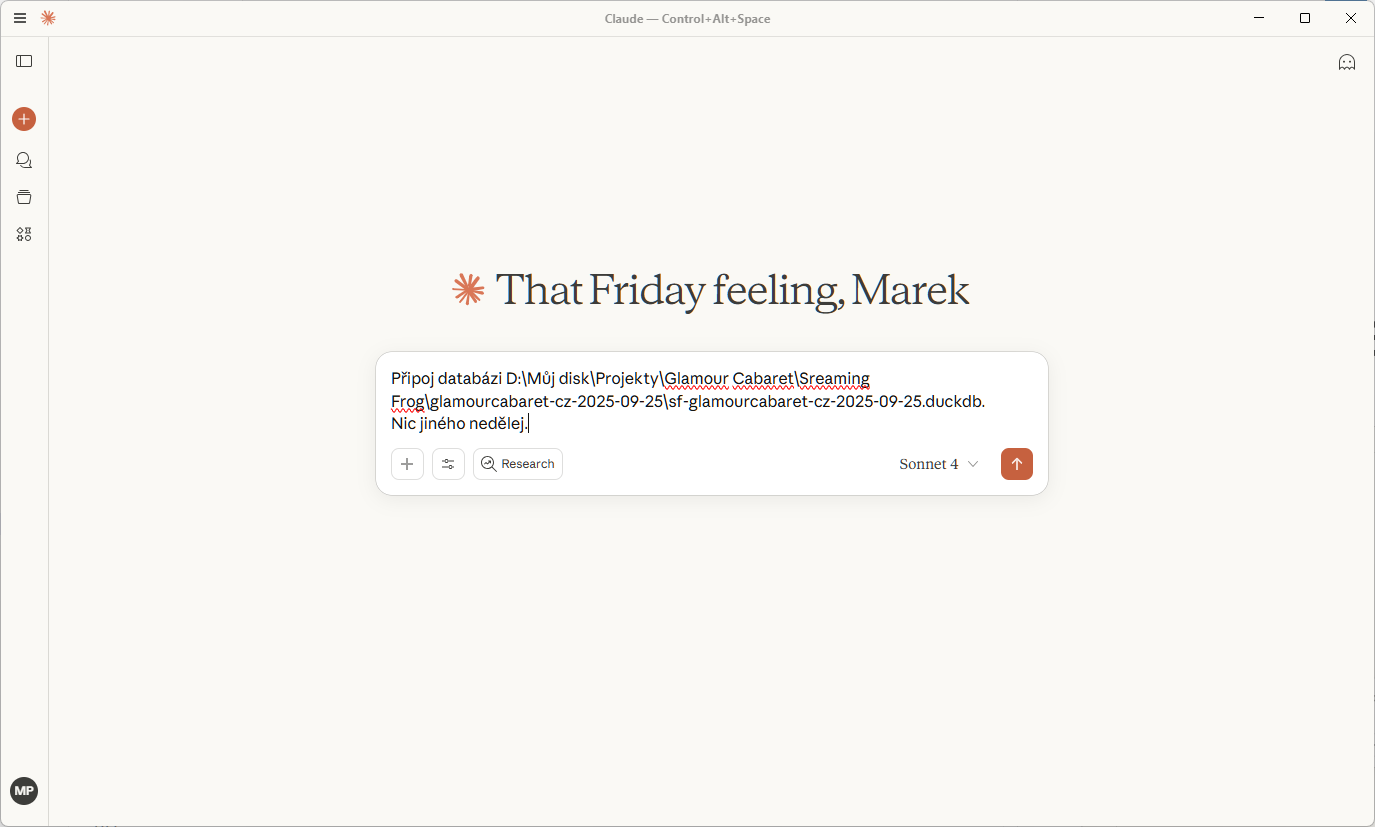
Databáze připojena
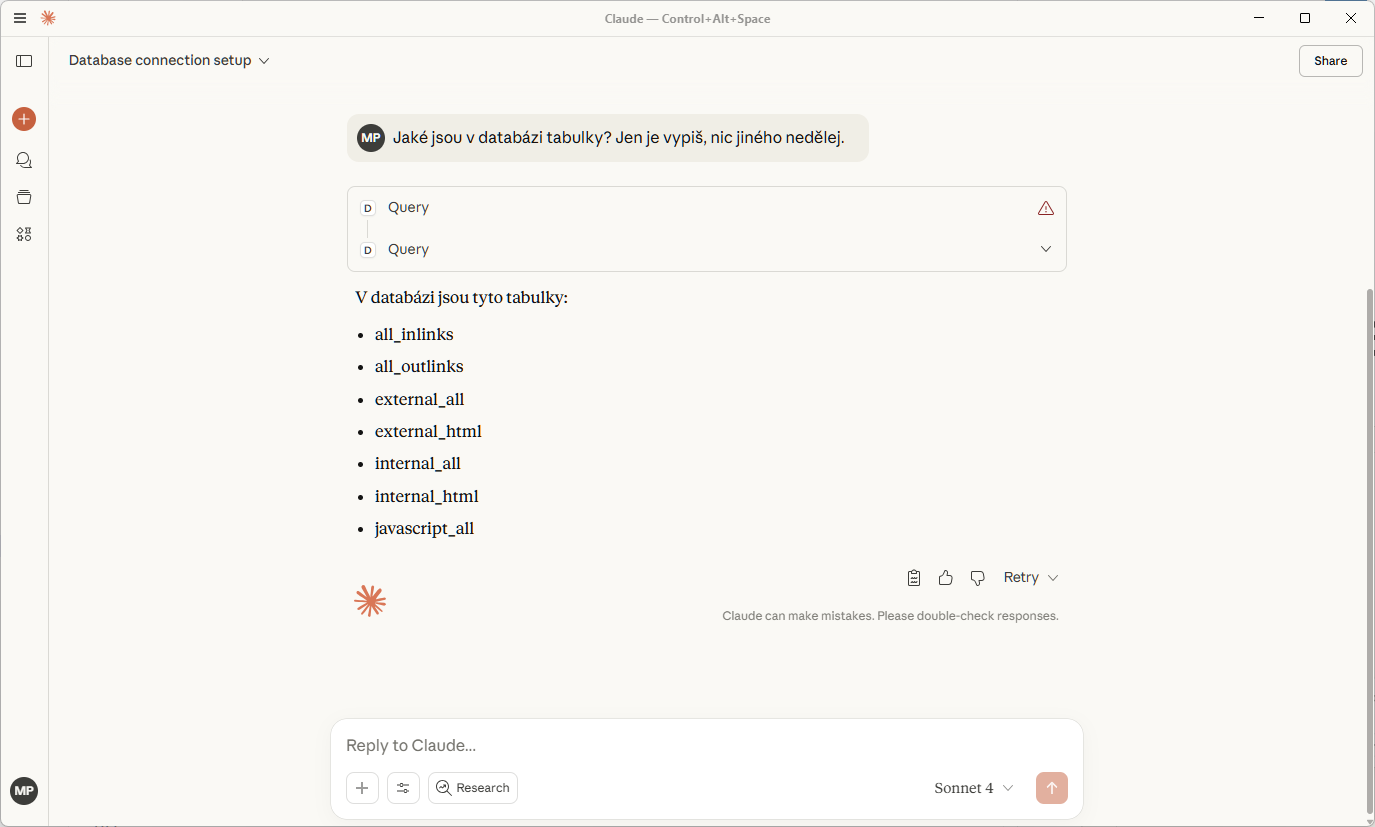
Zkontroluju dostupné tabulky
A pak už se jen ptám
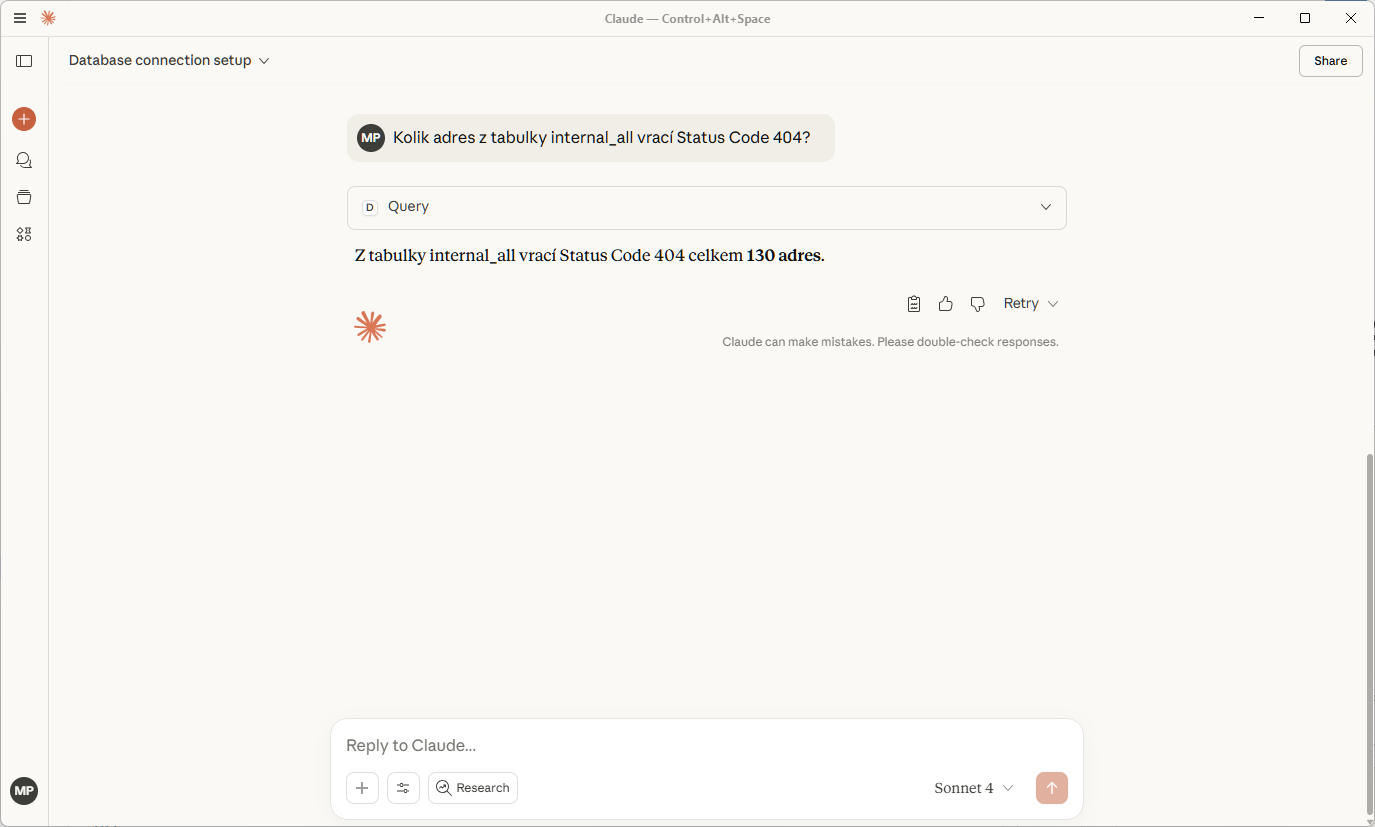
A pak už se jen ptám
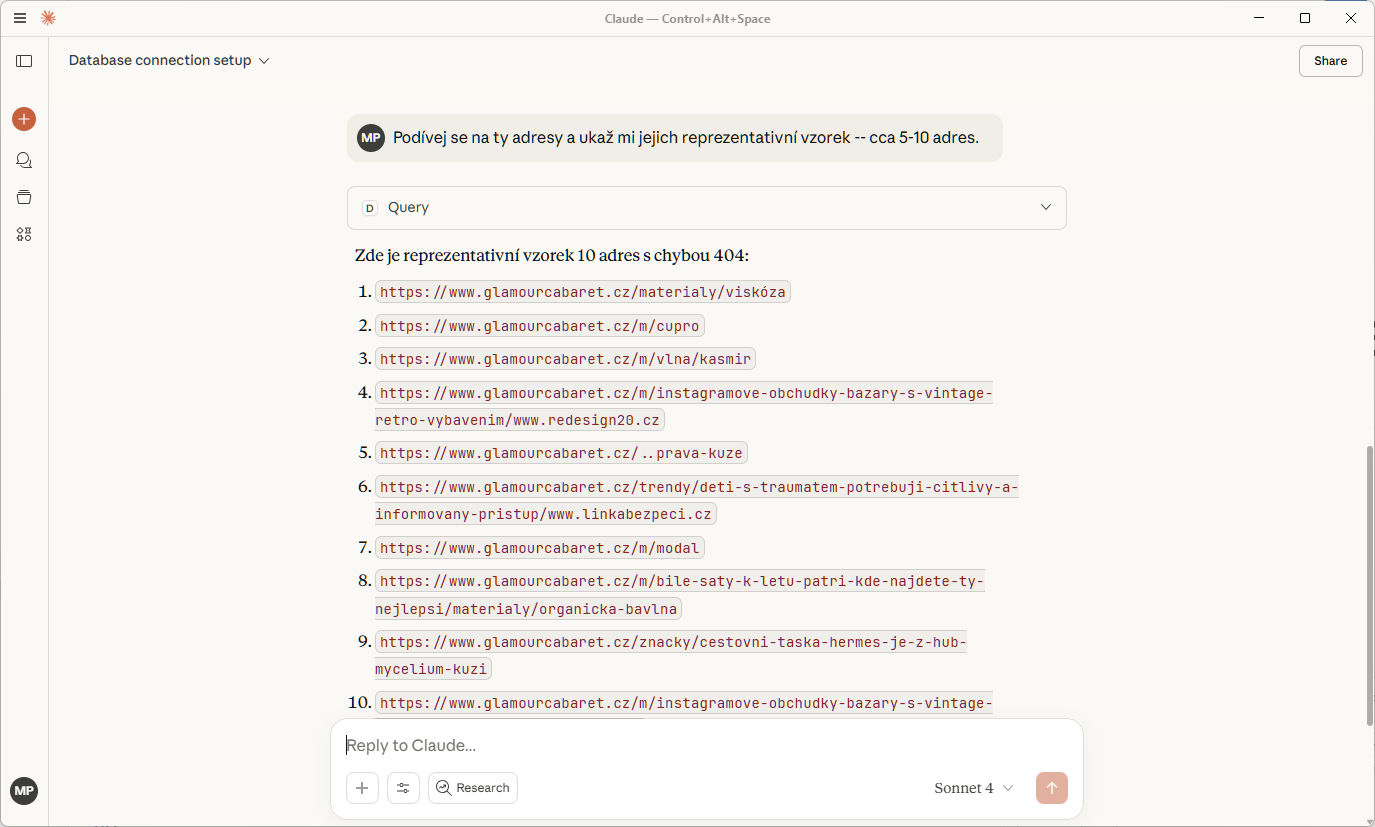
A pak už se jen ptám
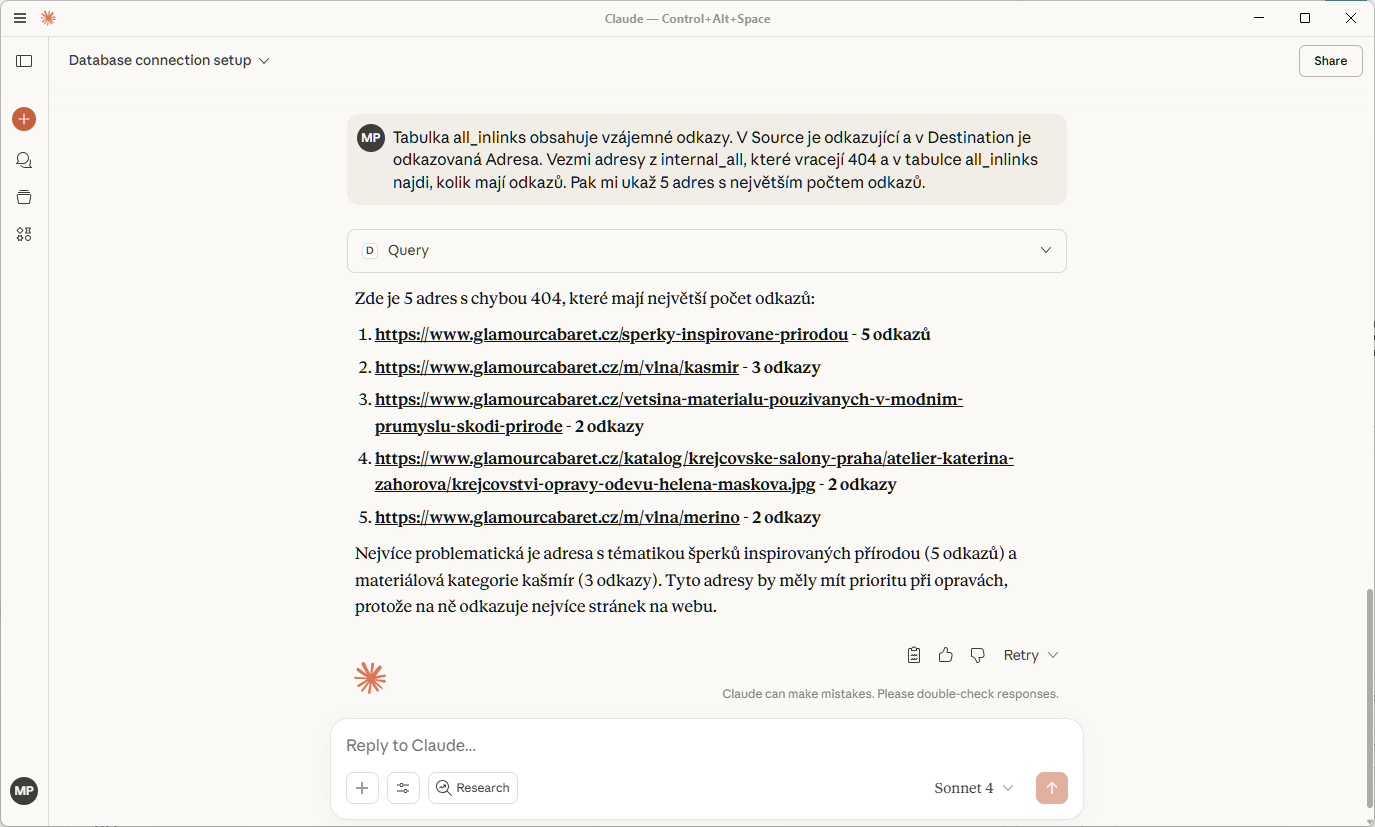
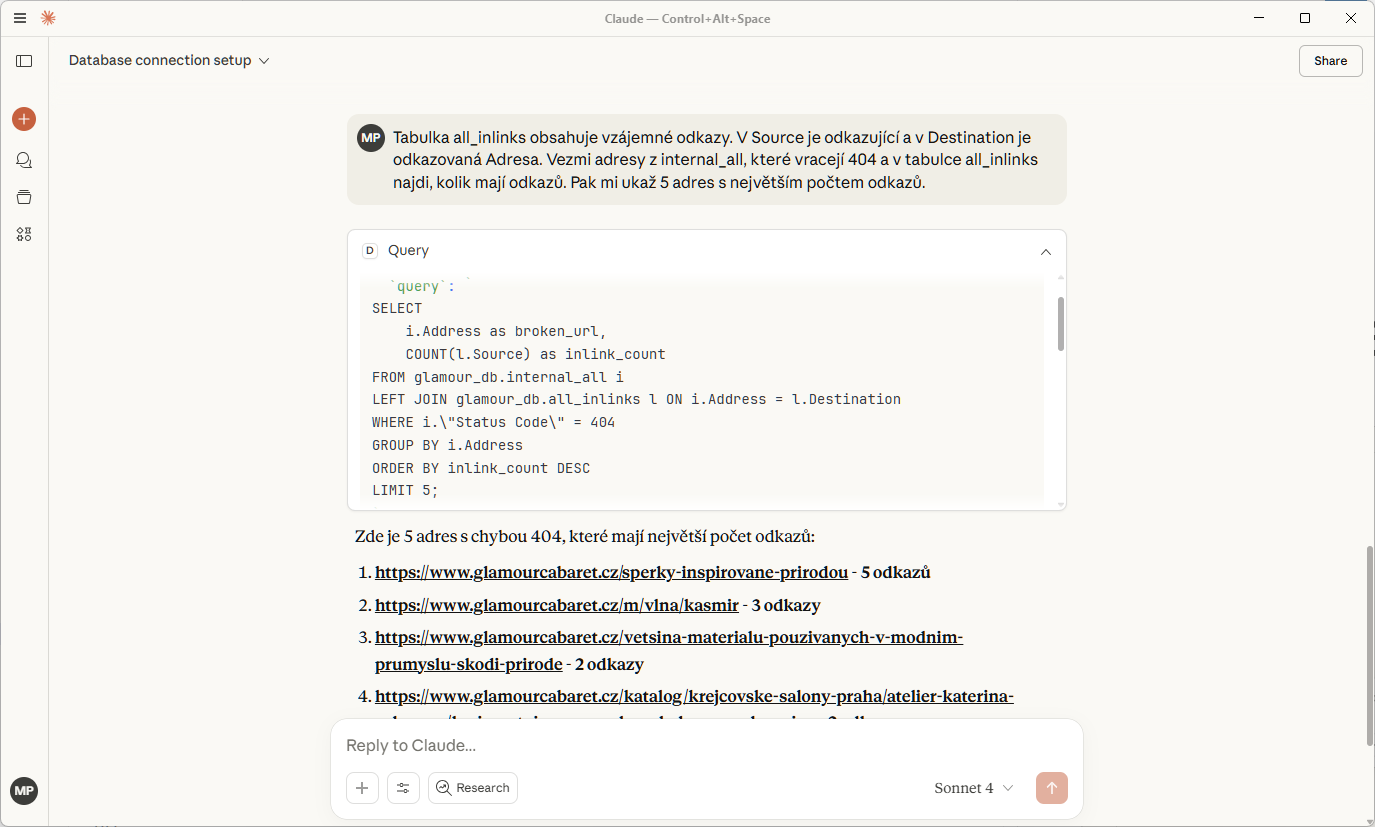
Zvládl i join. To si zaslouží potlesk!
Příklady SQL dotazů
Přímé odkazy na interní chyby 4xx
Pro odkazy na externí 4xx se zneguje Destination LIKE 'https://www.example.com/%'.
Přesměrování na interní chyby 4xx
Vzor obecného dotazu na odkazy na vybrané stránky
Příklad z internal_html vybere určité stránky a pomocí JOIN k nim získá odkazy z all_inlinks. Hodí se pro všechny případy, kdy je potřeba získat odkazy na něco a v samotné tabulce all_inlinks nejsou data potřebná pro výběr řádků.
Neindexovatelné stránky v sitemapách
Sirotci – stránky odkazované jen z XML sitemap
Indexovatelné stránky, které nejsou v XML sitemapách
Co by šlo vylepšit
Podrobné instrukce pro AI
- projekty, custom GPT, Gems
- claude.md pro Claude Code
DuckLake
- Formát pro data lakes od autorů DuckDb
- Šlo by propojit víc crawlů stejného webu.
- Šlo by cestovat časem – porovnávat crawly z různé doby.
Děkuju za pozornost
- Rád vám pomůžu, napište mi na mprokop@prokopsw.cz.